CH391L
Contents |
CH391L Bioinformatics
Course unique #: 52990
Lectures: Tuesday/Thursday 12:30 – 2:00 PM in WEL 3.402
Instructor: Edward Marcotte, marcotte@icmb.utexas.edu
- Office hours: Wednesdays 2:00 – 3:00 PM in MBB 3.210AA Phone: 471-5435
TA: Taejoon Kwon, taejoon.kwon at mail dot utexas dot edu
- TA Office hours: Tuesday/Thursday 10:00 – 11:00 AM in MBB 3.210A Phone: 232-3919
Lectures & Handouts
May 5, 2011 - Some of the publicly-viewable final projects
- Distinguishing Somatically Mutated Antibodies from 454 Pyrosequencing Errors
- Finding phenologs: mapping complex orthology data using SOMs
- Determination of antigen-specific antibody design criteria using cluster analysis
- Prediction of improved aglycosylated Fc variants for FcγRs via structure based computation
- Determination of Evolutionary Environment via Phylogenetic Analysis
- Variance in Human Cys-Loop Family of Transmembrane Proteins as Quantified by the Boltzman Distribution
- Genome sequencing links natural competence to CRISPR defense systems in the opportunistic pathogen Aggregatibacter actinomycetemcomitans
- Global analysis of ChIP-seq data
- Exploring R2R3 MYBs in Arabidopsis
- Searching for tissue-specific genomic neighborhoods
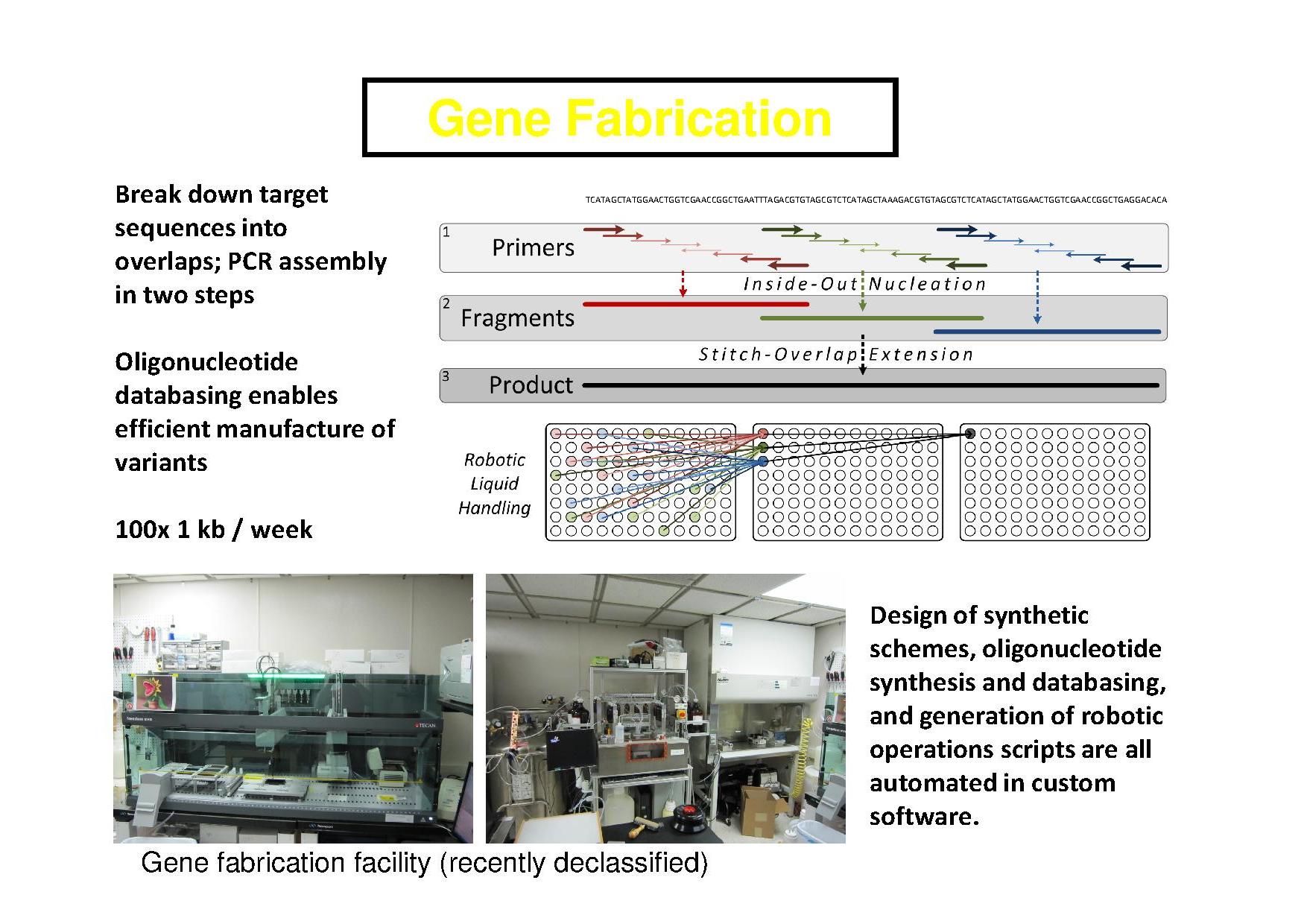
May 3, 2011 - Synthetic biology
- Genome Transplantation
- JCVI-1.0
- A DNA Fab, courtesy of Andy Ellington
- One step genome assembly in yeast
- New cells from yeast genomic clones
- A new cell from a chemically synthesized genome, SOM
{kind=link}
April 28, 2011 - Synthetic biology
- The infamous repressilator
- The infamous toggle switch
- The Gillespie algorithm
- Handout on Gillespie
- Bacterial photography
- Edge detector
April 26, 2011 - Network alignment and motifs
April 21, 2011 - Networks
April 19, 2011 - Networks
- Hox genes
- Module networks
- Small world networks
- Dijkstra's algorithm
- Scale-free networks
- Lethality-centrality
- Yeast complexes
April 14, 2011 - Networks
- mirSOM
- Metabolic networks: The wall chart
- Transcriptional networks: ChIP-Chip & ChIP-SEQ, large-scale screens-1, large-scale screens-2, and heritability
- Protein interactions: overview, large-scale screens & networks
- Protein interaction extent and quality
April 12, 2011 - Motifs
- Two linear algebra refreshers: 1, 2
- NBT Primer - What are motifs?
- NBT Primer - How does motif discovery work?
- The biochemical basis of a particular motif
- Gibbs Sampling
- AlignAce
April 7, 2011 - PCA/SVD
April 5, 2011 - Classification
- The best open software for do-it-yourself data mining: Weka
- Mahalanobis
- SVD of gene expression 1, 2
- European men, their genomes, and their geography
Mar 31, 2011 - Clustering & Classification
Mar 29, 2011 - Clustering 2
- Fuzzy k-means
- SOM gene expression
- & links to various applications of SOMs: 1, 2, 3, 4, and a picture of Teuvo himself
- (From TA) You can run SOM clustering with Open Source Clustering package (alternative to Eisen's Cluster) with '-s' option, or GUI option. See http://bonsai.hgc.jp/~mdehoon/software/cluster/manual/SOM.html#SOM for detail. (FYI, it also supports PCA). If you are not happy with Cluster SOM function, statistical package R also provides a package for SOM (http://cran.r-project.org/web/packages/som/index.html).
An assortment of datasets for Problem Set 4, due Apr. 12, 2011
- Yeast protein sequences
- Yeast protein phylogenetic profiles
- Yeast mRNA expression profiles
- For simplicity, here are the summary files (edited slightly, showing total read counts, counts of reads where F3 and F5 map to the same organism, counts of F3 and counts of F5 reads) of all of the searches on the 5 environmental samples:
Mar 24, 2011 - Clustering
- News of the day: multiple myeloma cancer genomes
- Phylogenetic profiles
- Review of phylogenetic profiles
- Example phylo profiles from Neurospora
- B cell lymphomas
- Primer on clustering
- K-means example (.ppt)
{kind=link}
Mar 22, 2011 - Gene expression
- Gene expression by ESTs
- Gene expression by SAGE
- Affy microarrays 1
- Affy microarrays 2
- cDNA microarrays
- Clustering by gene expression
- Cell cycle data
- Clustering
Mar 8, 2011 - Assembling genomes + next-gen sequencing
- We're running a bit behind on our next-gen sequencing datasets, which were intended for Problem Set 3. I'll plan to add these data to Problem Set 4. Instead, for Problem Set 3, I'll give credit for turning in one (full) paragraph laying out your planned work for your final course project. The deadline will be extended to March 10. (Turn them in by email. Remember, no class on the 10th.)
- Here are a few examples of final projects from previous years: 1, 2, 3, 4, 5
Mar 3, 2011 - Assembling genomes
- Due March 8 by email - One paragraph describing your plans for a final project
- Fly - the genome
- Fly - the genome assembly
- GigAssembler
Mar 1, 2011 - Assembling genomes
- Next-gen sequencing news from the latest Science
- Prenatal screening by sequencing
- The H. influenzae genome paper
- BACs, YACs, and cosmids, oh my!
Feb 24, 2011 - Gene finding
- The GENSCAN paper
- Evaluating gene annotations: GASP, EGASP, & nGASP
- HW2.1
- T segment histogram
Feb 22, 2011 - HMMs and gene finding
Feb 17, 2011 - HMMs
- HMM primer
- Problem Set 2, due Feb. 24, 2011
- State sequences
- Soluble sequences
- Transmembrane sequences
Feb 15, 2011 - Profiles
- A commentary on computational challenges arising from DNA sequencing
- The remarkable growth of Genbank, and similarly, UniProt
Feb 10, 2011 - BLAST
- The original BLAST paper
- Teaching BLAST
- The protein homology graph paper. Just for fun, here's a link to a stylized version we exhibited in the engaging Design and the Elastic Mind show at New York's Museum of Modern Art.
Feb 8, 2011 - Sequence Alignment III
- A few examples of proteins with internally repetitive sequences: 1, 2, 3
- Repeats in the human genome, tallied here
{kind=link}
Feb 3, 2011 - Sequence Alignment II
- An example of dynamic programming using Excel, created by Michael Hoffman (a former CH391L student; you can read more about Michael here)
- Dynamic programming primer
Jan 27, 2011 - Sequence Alignment I
- Taejoon's presentation file
- BLOSUM primer
- The original BLOSUM paper (hot off the presses from 1992!)
Jan 25, 2011 - Perl primer
- Problem Set 1, due Feb. 8, 2011
- E. coli genome
- T. volcanium genome (to a student who asked me about 'a strange character' in this file, I checked this file and found no strange 'character' in this file. -- Taejoon)
- 3 mystery genes (for Problem 5): Mgene1, Mgene2, Mgene3
Syllabus & course outline
An introduction to computational biology and bioinformatics. The course covers typical data, data analysis, and algorithms encountered in computational biology. Topics will include introductory probability and statistics, basics of programming, protein and nucleic acid sequence analysis, genome sequencing and assembly, protein structure prediction, analysis of DNA microarray data, data clustering, biological pattern recognition, and biological networks.
Open to graduate students and upper division undergraduates in natural sciences and engineering.
Prerequisites: Basic familiarity with molecular biology, statistics & computing, but realistically, it is expected that students will have extremely varied backgrounds.
Note that this is not a course on practical sequence analysis or using web-based tools. Although we will use a number of these to help illustrate points, the focus of the course will be on learning the underlying algorithms and exploratory data analyses and their applications.
Most of the lectures will be from research articles and handouts, with some material from the...
Recommended text (for sequence analysis): Biological sequence analysis, by R. Durbin, S. Eddy, A. Krogh, G. Mitchison (Cambridge University Press),
For non-molecular biologists, I highly recommend (really!) The Cartoon Guide to Genetics (Gonick/Wheelis)
For biologists rusty on their stats, The Cartoon Guide to Statistics (Gonick/Smith) is also very good.
Some online references:
An online bioinformatics course
Various bioinformatics algorithms
Assorted bioinformatics resources on the web
Online probability texts: #1, #2, #3
No exams will be given. Grades will be based on 4 problem sets (given every 2 weeks and counting 15% each towards the final grade) and a course project (40% of final grade), which can be individual or collaborative. If collaborative, cross-discipline collaborations are encouraged. The course project will consist of a research paper or project on a bioinformatics topic chosen by the student (with approval by the instructor) containing an element of independent computational biology research (e.g. calculation, programming, database analysis, etc.). This will be turned in as a link to a web page.
The final project is due on May 3, 2011.
From the TA
- How to make web site for the final project?
- CH391L/UTpond Environmental samples.
- If you don't have a unix/linux account to do the homework and/or project, send email to 'taejoon.kwon at mail dot utexas dot edu'.
- CH391L/Connecting_Server (If you don't know how to use the account info, this are the instructions.)
- If you are having trouble transferring files from your computer to server, here are some GUI programs that can help you:
- http://winscp.net/eng/index.php (WinSCP, Windows)
- http://cyberduck.ch/ (CyberDuck, Mac)
- http://filezilla-project.org/ (FileZilla, all platforms)
- CH391L/PERL_Programming Basic information about PERL programming environment
- CH391L/NucleotideFrequency PERL program to count nucleotide/dinucleotide frequency (Homework 1).
- CH391L/BLOSUM PERL program for BLOSUM scoring matrix analysis (Homework 1).
- CH391L/DynamicProgramming PERL example code for dynamic programming.
- CH391L/HiddenMarkovModel PERL example code for HMM (Viterbi Algorithm).